
This post was featured in our Cognilytica Newsletter, with additional details. Didn’t get the newsletter? Sign up here
We’re excited to announce today the latest iteration of the Cognilytica Voice Assistant Benchmark. Conversational interface-based devices are starting to take off with devices and technology like Amazon Alexa, Google Home, Apple Siri, Microsoft Cortana, and an increasing number of new entrants into a space. Cognilytica calls these devices “voice assistants”, rather than the less-useful term “smart speakers”. A smart speaker conjures up a primarily output oriented device that aims to replace keyboard or button interaction with voice commands. Yet, that seems to be a particularly trivial application for the significant investments and competitive posture that these device manufacturers are taking. The real play is something bigger than just a speaker you can control with your voice. Rather than just being passive devices, intelligent conversational assistants can proactively act on your behalf, performing tasks that require interaction with other humans, and perhaps soon, other conversational assistants on the other end. The power is not in the speaker, but in the cloud-based technology that powers the device.
Testing Cloud-based Conversational Intelligence Capabilities of Edge Voice Assistants
Voice assistants are voice-based conversational interfaces paired with intelligent cloud-based back-ends. The device itself provides basic Natural Language Processing (NLP) and Natural Language Generation (NLG) capabilities, and the back-end intelligence gives these devices AI-powered intelligence. Can the conversational agents understand when you’re comparing two things together? Do they understand implicit unspoken things that require common sense or cultural knowledge? For example, a conversational agent scheduling a hair appointment should know that you shouldn’t schedule a hair cut a few days after your last hair cut, or schedule a root canal dentist appointment right before a dinner party. These are things that humans can do because we have knowledge and intelligence and common sense.
Cognilytica is focused on the application of AI to the practical needs of businesses, and because we believe voice assistants can be useful to those businesses. As such, we need to understand the current state of the voice assistant market. We care about what happens when the NLP does its processing and those outputs are provided as input to an intelligent back-end system. We want to know — just how intelligent is the AI back-end?
Yes, We Know Voice Assistants Aren’t Very Intelligent… But the Bar is Moving.
Some of you might be thinking that it’s obvious that these voice assistants aren’t particularly intelligent. Surely, you’re thinking, anyone who has spent any amount of time focused on AI or NLP or other areas of cognitive technology should know that these devices lack critical intelligence capabilities. Are we just naive to test these devices against what seems to be an obvious lack of capabilities? It doesn’t take an AI expert to know these devices aren’t intelligent – just ask any five year old who has spent any amount of time with Alexa, Siri, Google Home, or Cortana.
However, it’s not obvious that these devices are not intended to be more intelligent than they currently are. Certainly if you look at the examples of use cases from Amazon and Google they will show their devices being used not just to play music or execute skills, but rather as a companion for critical business tasks. Some vendors are demoing their devices being used to make real-world calls to real-world businesses to perform real-world tasks. This is not just playing music or telling you the weather. This requires at least a minimum level of intelligence to perform without frustrating the user. And so, without an understanding of what the limitations of these devices intelligence really are, we’re left wondering what sort of applications these voice assistants are best suited for.
Purpose of Benchmark: Measure the Current State of Intelligence in Voice Assistants
All the voice assistant manufacturers are continuing to iterate on the capabilities of their cloud-based AI infrastructure, this means that the level of intelligence of these devices is changing on almost a daily basis. What might have been a “dumb” question to ask a mere few months ago might now be easily addressed by the device. If you’re basing the assumptions of your interactions on what you thought you knew about the intelligence of these devices, your assumptions will quickly be obsolete.
If you’re building Voice-based Skills or Capabilities on Voice Assistant Platforms, you NEED to Pay Attention
If you’re an enterprise end-user building skills or capabilities on top of these devices, or a vendor building add-on capabilities, then you definitely need to know not only what these devices are capable of currently but how they are changing over time. You might be forced to build intelligence into your own skills that compensate for the lack of capabilities by the vendor in that area. Or you might spend a lot of time building that capability to realize that the vendor is now already providing that base level of functionality. Even if you think you’re an AI expert with nothing to learn from this benchmark, you are mistaken. This is a constantly evolving industry and today’s assumptions are tomorrow’s mistakes. Follow this benchmark as we continue to iterate.
Open, Verifiable, Transparent. Your Input Needed.
The Cognilytica Voice Assistant Benchmark is meant to be open, self-verifiable, and transparent. You should be able to independently verify each of the benchmark results we have posted on the voice assistants tested. You can also test your own voice assistant based on proprietary technology or ones not listed here. If you are interested in having a voice assistant added to our regular quarterly benchmark that we are not already testing, please contact us.
Likewise, we are constantly iterating the list of benchmark questions asked. With that, we would like to get your feedback on the questions that we are asking as well as feedback on future questions that should be asked. Please reach out to us with feedback on what we should be asking or how to modify the list of questions for an upcoming benchmark version.
This is not a ranking!
The Cognilytica Voice Assistant Benchmark is used as a way of measuring performance against an “ideal” metric, not as a way of ranking between different vendor technology implementations. The goal of this benchmark is that all vendors should perform at the most intelligent levels eventually. As such, we will continue to measure how well the voice assistants are performing against the benchmark, not against each other.
Benchmark Methodology
In the current iteration of the Cognilytica Voice Assistant benchmark, there are 10 questions each in 10 categories, for a total of 100 questions asked, with an additional 10 calibration questions to make sure that the devices and benchmark setup is working as intended. To avoid problems relating to accents, differences in user voice, and other human-introduced errors, each of the questions are asked using a computer generated voice. Each benchmark result specifies which computer generated voice was used so that you can replicate thebenchmark.
The responses from the voice assistants are then categorized into one of four categories as detailed below:
| Response Category | Classification Detail |
| Category 0 | Did not understand or provides a link to a search with the question asked requiring human to do all the work. |
| Category 1 | Provided an irrelevant or incorrect answer |
| Category 2 | Provides a relevant response, but with a long list of responses or a reference to an online site that requires the human to understand the proper answer. Not a default search but rather a “guess” conversational response that makes human do some of the work. |
| Category 3 | Provided a correct answer conversationally (did not default to a search that requires the human to do work to determine correct answer) |
Rather than create an absolute score for each tested voice assistant, the benchmark shows how many responses were generated for each category listed above. Category 3 responses are considered to be the most “intelligent” and Category 0 are the least “intelligent”, with Category 1 and Category 2 being sub-optimal responses. Total scores by category are not as important as understanding the maximal score in a particular category. This is because some voice assistants respond better for particular categories of questions than others. See the commentary for more information on our analysis of the results per category.
The calibration questions are not meant to test the specific intelligence of the devices, but rather to make sure the setup is working and that the expected answers were generated by the voice assistants. To prevent any issues with regards to accents, vocal tone, volume, or other speech inconsistencies, we used a voice generation tool to speak the questions to the various devices.
As further proof of the veracity of our benchmark, we video record all of the questions being asked along with the responses so you can see how the voice assistants performed at the time of recording. We don’t want there to be any doubt that we got the results that we got, and that you can see how we performed the tests without any bias in our question answering or assignments of responses by category.
Results and Interesting Insights from the Latest Voice Assistant Benchmark
Insights from the Calibration Questions
All the voice assistants generated the expected responses for all the calibration questions asked, with one notable exception – the Microsoft Cortana voice assistant provided an irrelevant answer to the question of “What is 10 + 10?”. Interestingly, it only provided the irrelevant answer when the speech generator used specific voices. This seems to point to issues in speech processing.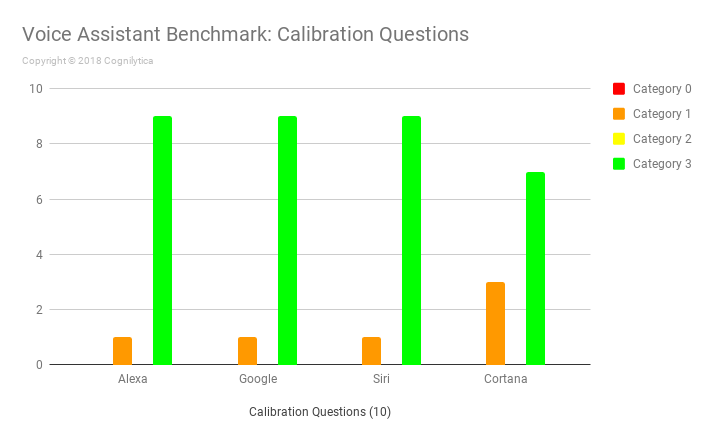
Insights from the Understanding Concepts Questions
In order for voice assistants to be helpful at various business-related tasks, they need to be able to understand certain concepts, such as distance, sizes, monetary measures, and other factors. Asking devices questions in relation to these concepts helps gain an understanding of whether the voice assistants are capable of handling concept-related queries.
In this latest benchmark, the differences in responses were very notable. Alexa got the most number of correct Category 3 responses to concept-related questions while Google Home struggled with questions as basic as “How much does a pound of peas weigh?” or “Will I need to shovel snow today?”. Alexa was able to answer these without any problem. Siri almost entirely defaulted to visual searches for questions like those, and Cortana exhibited better performance than Google and Siri, but fewer Category 3 responses than Alexa.
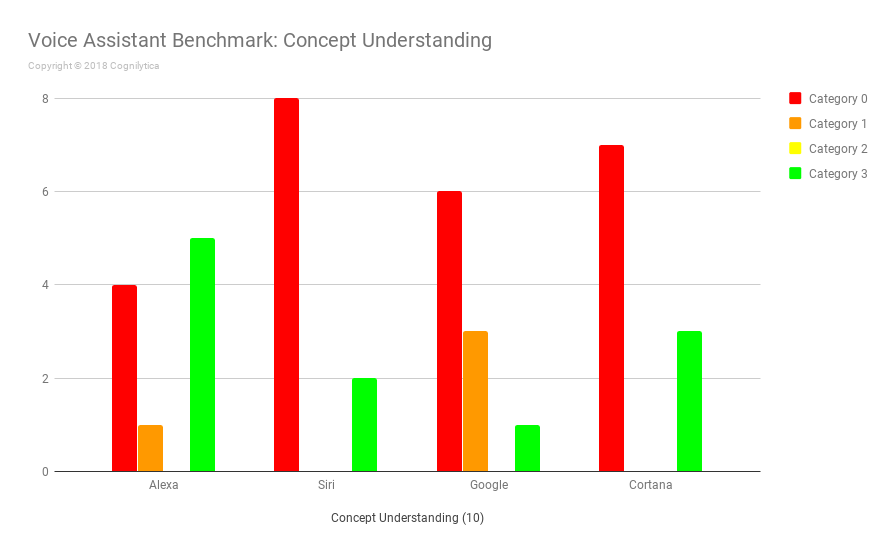
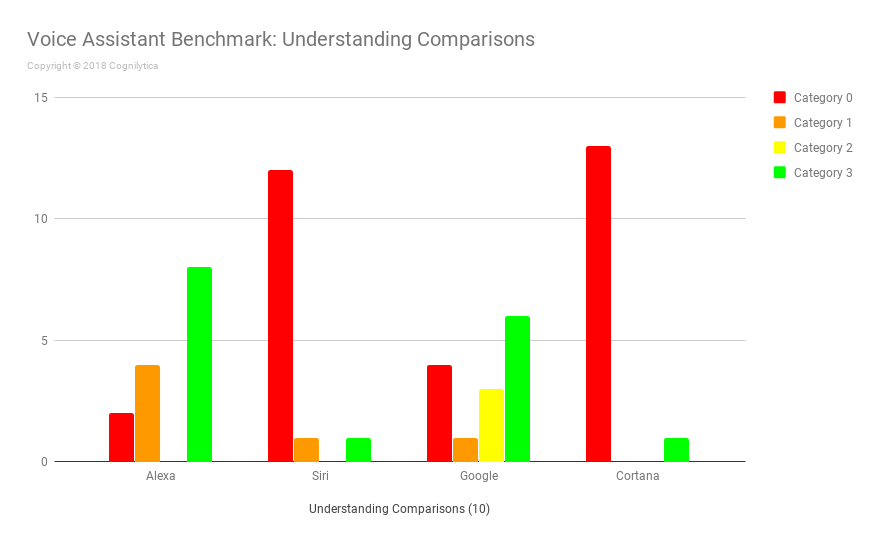
Insights from the Understanding Comparisons Questions
In order for voice assistants to be helpful at various business-related tasks, they need to be able to compare different concepts together, such as comparing relative size, amount, quantity, and other measures. Asking devices questions in relation to these comparisons helps gain an understanding of whether the voice assistants are capable of handling comparison-related queries.
In this latest benchmark, Cortana and Siri both showed that they were not able to respond to most, if not all, of our comparison-related benchmark questions. Alexa and Google, however had a reasonable number of Category 3 correct responses. Alexa provided incorrect or irrelevant answers to questions like “What is faster, a turtle or a cheetah?” while Google attempted to provide an answer by providing the speeds of both animals without directly answering the question (a Category 2 response).
Insights from the Understanding Cause & Effect Questions
In order for voice assistants to be helpful at various business-related tasks, they need to be able to understand what happens as a consequence of specified actions. Asking devices questions in relation to these causes and effects helps gain an understanding of whether the voice assistants are capable of handling queries that depend on certain outcomes.
In this latest benchmark, pretty much all of the voice assistants did poorly, not answering questions like “What color is burned toast?”. Curiously, while Alexa and Siri both failed to answer any questions at Category 3, Google and Cortana both answered the question “What happens when you melt ice?” with a satisfactory Category 3 response.

Insights from the Reasoning & Logic Questions
In order for voice assistants to be helpful at various business-related tasks, they need to be able to reason and deduce information based on what the speaker says. Asking devices various reasoning and logic-oriented questions helps gain an understanding of whether the voice assistants are capable of handling queries that require reasoning.
In this iteration of the benchmark, Siri had surprisingly strong Category 3 responses to questions like “Can you eat toxic food?” while others did not answer that question. Alexa answered two other reasoning questions with satisfactory Category 3 responses, while the rest either failed to respond to any of the questions or responded with incorrect or irrelevant answers. Google had a curious answer to the question, “What is the log of e?”, with a long answer that had the correct answer embedded in a long-winded answer that leaves the human scratching their head (a Category 2 response).
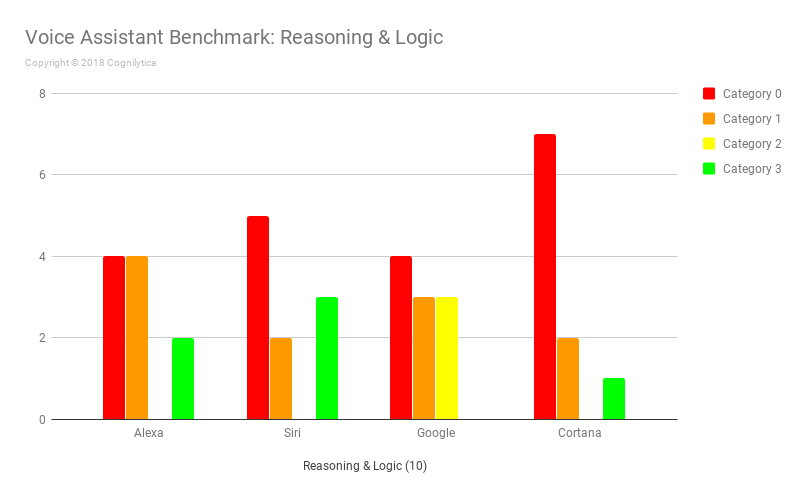
Insights from the Helpfulness Questions
Voice assistants need to be helpful in a wide variety of contexts. These questions aim to find out what sort of non-skill / third-party developer enhanced capabilities are inherent in the devices to provide helpful answers in respond to a wide range of questions.
In this benchmark we see some particularly profound and interesting results. The helpfulness of the voice assistants clearly has a huge dependency on what data these systems were trained on. Google is the most helpful, successfully answering questions like “How much protein is in a dozen eggs?” and “Where can I buy stamps?” while others puzzlingly can’t answer those questions. As we’ll see later, Google particularly shines with kitchen-related helpfulness. Cortana struggled to be helpful, resorting to default searches, and Siri answering the question “Where is the closest public restroom?”.

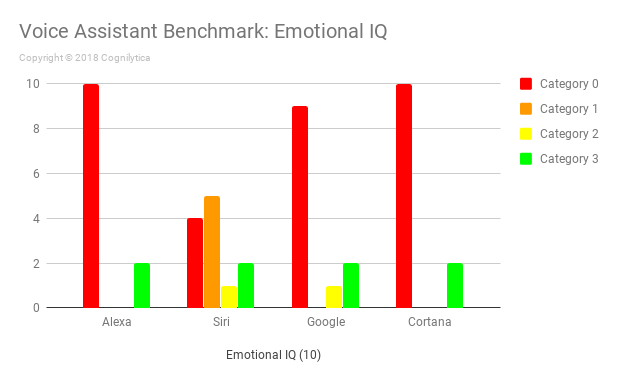
Insights from the Emotional IQ Questions
We all know that machines aren’t (yet) capable of feeling emotion. However, voice assistants need to be aware of human emotions and formulate responses that are emotion-relevant. These questions aim to determine the level to which tested voice assistants are capable of handling emotion-related questions or responding in an emotion-relevant manner.
In this benchmark, all the voice assistants do predictably poorly, only offering Category 3 responses for questions that ask for definition of emotion-related terms. Google makes an attempt to answer the question “What do you say when someone sneezes?”. It’s listed as a Category 2 response, but probably could be counted as Category 3 if you listen to the full, long-winded response. No pun intended.
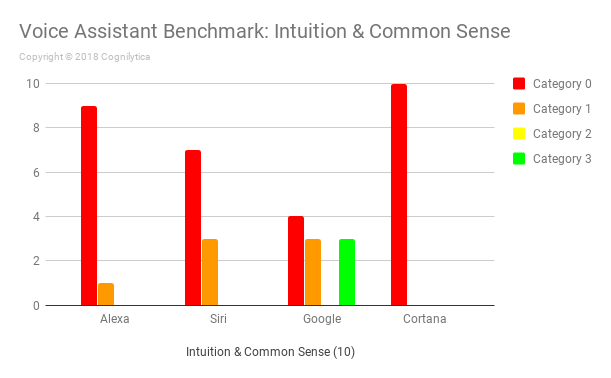
Insights from the Intuition and Common Sense Questions
Common sense is neither common nor always makes sense, and certainly machines have not been known to have either. However, voice assistant devices have AI systems that use training models that impart the common sense and intuition of their human-based designers. Furthermore, voice assistant users in a business context will make assumptions in their questions that might depend on common sense knowledge not specified. These questions aim to identify what common sense and intuition capabilities are inherent in this training data.
In this benchmark, all the voice assistants do predictably poorly in response to our questions. Google does attempt to answer questions like “What do I do if there’s a fire in the house?” and “Should I drink milk if I’m lactose intolerant?”, both of which are needlessly wordy, but might qualify as Category 3 answers. It provides an interesting, but irrelevant (Category 1) response to the question “Do books grow on trees?”.
Insights from the Winograd Schema Inspired Questions
The Winograd Schema is a format for asking questions of chatbots and other conversational computing devices to ascertain whether or not they truly understand the question asked and formulate a logical response. Winograd Schema Challenge formatted questions are often used in AI-related chatbot competitions, such as the one for the Loebner Prize. These questions draw on some of the Winograd Schema suggested questions as well as other questions that are inspired by the Winograd format to ascertain a level of knowledge in the tested voice assistants. See the Common Sense Reasoning site for more details on the Winograd Schema Challenge.
Predictably, all the voice assistants completely fail with Winograd Schema formatted questions. It takes real intelligence to know how to parse and understand sentences formulated that way.

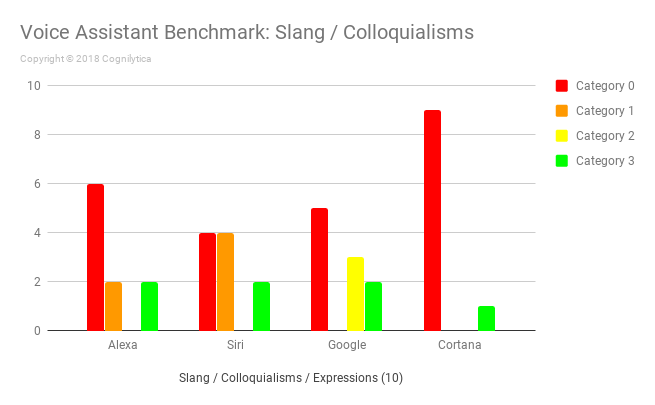
Insights from the Slang / Expressions Questions
Human speech doesn’t always fit in predictable or logical patterns. Sometimes humans speak with mannerisms that don’t have literal meaning or are culturally-relevant. Slang, expressions, and colloquialisms are highly language and region-dependent, but they form a core part of most human conversation. These questions aim to determine the level to which tested voice assistants have been trained to understand certain expressions or non-literal manners of speech.
Also predictably, slang and expressions are tough for voice assistants. They’re even tough for humans sometimes. Perhaps this is an unfair test, but truly intelligent devices should learn regional idioms and expressions and know how to handle questions that include those. Google provides humorous responses to “Does Howdy mean Hello?” and a long-winded answer to “In what state do you say “Aloha?”. Can you see a trend here with Google being particularly verbose? Alexa seems personally offended when you ask the question “If you’re sick, are you under the weather?”. This implies that Alexa does indeed understand that expression, even if it doesn’t answer the specific question.
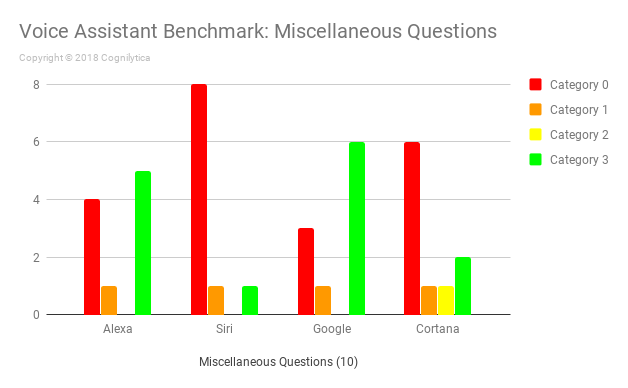
Additional Insights from the Miscellaneous Questions
These questions either don’t fit into one of the above categories or are additional questions that we didn’t have room to ask. These miscellaneous questions test voice assistants relevant to intelligence, understanding, and helpfulness.
In this benchmark, we can see where the sweet spot is for these various devices. Alexa shines with questions like “How old would George Washington be if he was alive today?” and “Where is the nearest bus stop?”, but can’t answer questions like “How long should you cook a 14 pound turkey?” or “What types of ticks can carry Lyme disease?”, both of which Google answered without any difficulty with Category 3 responses. Siri and Cortana defaulted mostly to search-based responses (making the human do all the work), but both devices did respond to “How old is George Washington?”, while Cortana did also answer or attempt to answer other questions.
Check out the Full Results of the July 2018 Voice Assistant Benchmark
So, how did they do as a whole? Check out all the responses by voice assistant below:
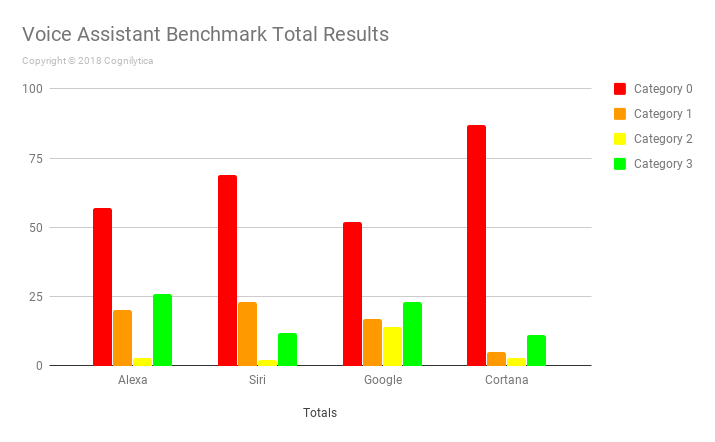
As you can see from the above results, as a whole, voice assistants have a long way to go before even half of the responses are in an acceptable Category 3. For the current benchmark, Alexa provided the most number of total Category 3 responses with 26 out of 100 questions answered in that category. Google follows close behind with 23 Category 3 responses. Siri and Cortana trail behind with only 12 and 11 Category 3 responses respectively.
If you’re interested in seeing how all the voice assistants responded to the version 1.0 benchmark questions and want to see actual video of those responses, check out the July 2018 Voice Assistant Benchmark page here. Keep in mind we are continuing to revise and add details to the page.
Where do we go from here?
Clearly we have a long way to go, which is why we’re going to continue to iterate and revisit this benchmark quarterly. As mentioned earlier, we’re not trying to rank and score these devices. From our intelligence-based perspective, they all fail. That doesn’t mean they’re not useful or helpful. Indeed, the vast majority of users are finding value and enjoyment in these devices. However, for these voice assistants to be used in the contexts and use cases that these vendors intend them to, we need for all these companies to step up the game. We know that getting to perfect Category 3 responses across all categories might be a nearly impossible task, but if we’re to advance the state of AI, then we need to help push this industry forward. That’s what we intend to continue to do with the Cognilytica Voice Assistant Benchmark and other industry measurement tools like it.
